PCにAI入れて会話してみて、学習させてみたいと思いました。
それをちゃっぴーに相談した結果、今日の流れになりました。
simple LoRA dreambooth trainerというものを導入することに。
AIの学習に使えるやつらしい。
Stable Diffusionをローカルに入れて画像生成するのにも使えます。
そこらへん、私の知識不足とちゃっぴーの認識違いで右往左往しました。
当初、語彙学習と評価学習をさせて、最終的に司書AIみたいなのを作るのが目標でした。
何かというと、私は過去に読んだ本とかの感想や自分視点の評価を書き貯めてます。
これを学習させ、ネット巡回させて、私向けのおすすめ新刊紹介とかさせようと画策。
で、それの第一段階として、私がよく使う言い回しや、私の趣味、私の価値観。
そういうのを、AIモデルに学習させよう、と思ったのです。
これを語彙学習(Text-to-LoRA)というらしい。
ちなみにやり方は割と簡単みたい。(まだやってないから不明だけど)
環境を作ったら、こんな感じで言葉を登録していくだけとのこと。
語彙: 灯
意味: 安心感、継続性、静かな希望
例文: 彼女の言葉は、夜の中で消えない小さな灯だった。
これをとりあえず200語くらいやってみろ、というのがちゃっぴーのお達しでした。
実際にやろうとして、結果的に画像生成して遊びましたというのが今回の記事。
なんかコードがぼこぼこ出てくる読み物的失敗談です。
これを参考にして導入する場合、10→2→3→5→11の順番でやるといいです。
或いは1で3.10.06をDLっての1→2→3→5→11でどうぞ。
※AUTOMATIC1111のインストールでGithubへのログイン画面出て失敗した人は11へ。
2025/12/17の不具合の件ならlaunch_utils.pyの書き換えで突破出来ます。
1:【Pythonのインストール】
以下のサイトからPythonとかいう謎な何かをDLってインストールします。
開発言語か何かだっけ?詳しくは知らない。
https://www.python.org/downloads/windows/
私が見た時点での3.10シリーズの最新はこれでした。
python-3.10.11-amd64
DLってインストールします。
その際、「Add Python to PATH」にチェックを入れること。
これやり忘れたら動かないので、アンインストールしてやり直し。
3.10.19にはしなくていいです。これはわかる人だけどうぞ。
ただ、もしかしたら正解は3.10.06なのかもしれない。今更だけど。
2:【Gitのインストール】
以下のサイトからGitという謎な何かをDLってインストールします。
更新や管理が楽になる道具らしい。stable Diffusionとか使うなら必須ぽい。
https://git-scm.com/install/windows
Git-2.52.0-64-bit
DLって適当にインストールします。
選択項目めちゃくちゃ多い。
まず最初の選択画面で、以下2つは確認。
Open Git Bash hare
Git LFS (Large File Support)
ここにチェック入ってなかったら入れろって誰かが言ってた。
詳細は知らない。この後は、基本的にNextを連打。
一応確認項目としては。
・Use Git from Git Bash only
・Git from the command line and also from 3rd-party software
・Use Git and optional Unix tools from the Command Prompt
これが出た時は、真ん中を選択。
3:【PythonとGitの確認】
CMD開いて
python –version
git –version
git lfs version
これ、1行づつ投下して、反応返ってくるかチェック。
反応なかったら、インストールフォルダの中のそれっぽい実行ファイル動かして確認。
それでも反応なかったら、失敗してるのでやり直し。
4:【simple LoRA dreambooth trainerの導入】
以下のサイトからsimple LoRA trainerをDLって解凍します。
あ、名前がdreamboothあったり無かったり、細かいことは気にしない。
時と共に作者の気分で変わったりなんだりするものらしい。詳細は知らない。
https://github.com/johnman3032/simple-lora-dreambooth-trainer
simple-lora-dreambooth-trainer
DLったら解凍します。
次に解凍した「フォルダの中」の、何もないとこでShift+右クリック。
「PowerShellウインドウをここで開く」を選択。
CMDだったりターミナルで開くだったり、言葉はいろいろ。
開いたら、以下のコマンドを投入。
python -m venv venv
続いて以下のコマンドを投入。
venv\Scripts\activate
ここで、なんかエラーが出たんで、以下を。
Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass
そして「Y」を入れる。
そののち、改めてvenv\Scripts\activateを。
続いてpipを最新版に。
python -m pip install –upgrade pip
次に必要ライブラリを入れる。
pip install -r requirements.txt
これはちょっと長いのでゆっくりお待ちください。
終わったら閉じずに次。
5:【Stable Diffusionの導入】
これ、いろいろ種類あります。
まずは公式サイトのベースモデルを。
Hugging Faceというサイトにアクセスして、以下のものをDLります。
https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5
v1-5-pruned-emaonly.safetensors 学習用
v1-5-pruned.safetensors 検証実践用
6:【フォルダとファイルを用意して実際に動かす】
以下のフォルダ、さっき作ったやつね?
\simple-lora-dreambooth-trainer-main
この中にmodelsフォルダを作ります。さっきDLしたのを突っ込みます。
次に適当にtrainフォルダを作ります。
その中にimagesフォルダとtextフォルダを作ります。
textフォルダの中に適当なテキストファイルを作って、中に学習させたい言葉を書きます。
で、これをテキストファイルに入れて保存。
これらのフォルダ名やファイル名は適当で大丈夫です。
好きな名前で問題無し。でも日本語名はやめたほうがいいと思う。英数字で。
7:【実際に動かす】
手順の4で用意したPowerShellの画面に戻ります。
以下を投入。実際この辺りは、ちゃっぴーにでも聞いてください。
python train_dreambooth.py –pretrained_model_name_or_path runwayml/stable-diffusion-v1-5 –instance_data_dir train\text –instance_prompt “akari_vocab” –output_dir output\akari_lora –resolution 512 –train_batch_size 1 –gradient_accumulation_steps 1 –learning_rate 1e-4 –lr_scheduler constant –max_train_steps 100 –checkpointing_steps 50 –mixed_precision fp16
8:【失敗というか方向が間違ってたことが判明】
***** Running training *****
Num examples = 1
Num batches each epoch = 1
Num Epochs = 100
学習自体は成功したらしい。
PIL.UnidentifiedImageError:
cannot identify image file ‘train\\text\\vocab_akari.txt’
でも、なんかテキストじゃなくて画像寄越せよってエラーで止まったらしい。
どうも、今回やってたのは語彙学習メインじゃなくて、画像主体だった模様。
ということで、今回の話は一旦終了です。
語彙学習をさせるという目的は達成出来てないんで失敗。
simple LoRA dreambooth trainerを動かして画像学習させる方法としては成功。
ということで、これはこのまま、後日のために残しておきます。
お疲れ様でした。以下後日談的なその後の話。
8.5【今後の方針策定】
以下ちゃっぴーとの会話抜粋。
1:画像生成でもいいので、まずGUIでAI学習を触って流れを把握し、成果物を出す。
2:主目的の語彙学習を実践する。GUIでもCUIでも可。
3:私の好みの本とかを学習させた図書館司書AIみたいなものを作る。
まずこれの1について。
目的は一通りの流れを抑えるために、確実に成功させること。
ということで、検索で一番多く出てくる「Web UI / AUTOMATIC1111」というものを試そうと思う。
詳しいことは知らないけど、一般的には定番らしい。
2については「Text generation web UI」というものがあるみたい。
こちらも詳細はほとんど調べてないけど、一定の事例は見つけた。
最後3については、2までを習得したらその先でやることなので、今は詳細については検討しない。
9:【Python 3.10.11のアンインストール】
いったん語彙学習の導入する前に、世の中に広く出回ってる画像学習やることにしました。
ということで、Python 3.10.11をPython 3.10.06に戻します。
別に戻さなくても動かせるっぽいけど、今回は安全ルートで行きます。
設定、アプリからPython 3.10.11のアンインストール。
Python Launcherは残した。
システム環境変数を開いて中を確認。
ユーザー環境とシステム環境にPythonや310と記載されたものがあるか確認。
あったら削除。
CMDにpython –versionを投入、何も返ってこないのを確認。
10:【Python 3.10.06のインストール】
Python 3.10.6のWindows installer (64-bit)のDL。
Add Python to PATHをチェックしてインストール開始。
CMDにpython –versionを投入、Python 3.10.6を確認。
Git入れてない人は2のステップに戻ってGit入れてから11へ。
11:【AUTOMATIC1111のインストール】
適当にフォルダ作って、CMDで該当の場所に移動して以下を投入。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
該当のフォルダに入って以下を投入。
webui-user.bat
途中でGithubの認証画面が出て失敗。
2025/12/17辺りから出てる不具合らしい。
以下の中身を書き換え。2025/01/19時点では以下のやり方で突破可能。
stable-diffusion-webui/modules/launch_utils.py
410行目付近の
stable_diffusion_repo = os.environ.get(
‘STABLE_DIFFUSION_REPO’,
“https://github.com/Stability-AI/stablediffusion.git”
)
↑を↓に変更。
stable_diffusion_repo = os.environ.get(
‘STABLE_DIFFUSION_REPO’,
“https://github.com/joypaul162/Stability-AI-stablediffusion.git”
)
で、改めてwebui.batを動かして成功。00012:【遊んでみた】
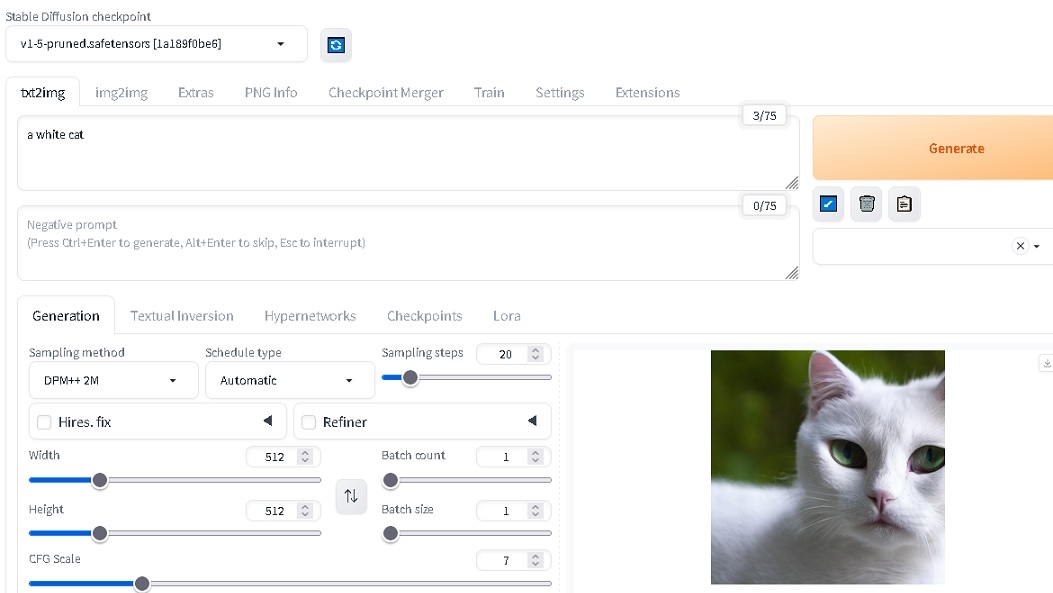
勝手にブラウザのhttp://127.0.0.1:7860/が開きます。
左上のところでモデル選んで、txt2imgに白猫出せ(a white cat)って入れて生成。
SS右側の猫が出ました。これめっちゃ簡単なのね。

適当に生成して遊んでみた。
このくらい↑の画質ならRTX3050で10枚生成するのに1分くらい。
文章生成より画像生成の方が軽い感じでした。

さっきの画像を、写実寄りにして出力するとこんな感じ。
多分だけど、左の子は風景要素に引っ張られて北欧風の顔立ちに。
逆に右の子は着物要素に引っ張られて和風な顔立ちに寄ったっぽいです。
なんというか、世の中の技術進歩って凄いなぁと思いました。
あとこれ、動画にして動かすことも出来るみたい。
どんだけー。
ただ、やってみて思ったのは、私は画像生成にはあまり興味がないみたいです。
生成出来るのはいいけど、生成したい対象が特に思い浮かばない。
私としては、AIとは文章でのやり取りする方が好きなようです。
とりあえず次はText generation web UIに挑戦かなぁ。


自分もAI(GPT)に聞いてAIの学習をしようと色々やりましたが
GPTの場合Geminiと違って最新情報には弱い事もあり,自分の知識ではGPUの互換性でかなり苦労しましたが色々自分用にカスタマイズしていくというのは楽しいですね
半分(以上?)放置ゲーと化した今の黒い砂漠とも相性がいいのはかなりありがたいです