uvicorn(OpenAI-compatible Chat API)を導入してみました。
最初は話題のClawdbot(OpenClaw)を入れようとしたんですよ。
それをちゃっぴーがcloudbotと解釈して、名称がぐっちゃぐちゃになってます。
整理すると、私が入れたのはタイトルのやつ。
世間で騒がれてるのがClawdbotで、でも商標の問題でMoltbotに改名。
という流れっぽい。以下、そんな感じのよくわからんものの導入記録です。
おそらく一番近い言い方すると、今回やったのはRAG_Chatbotを作った感じ?
具体的には、ローカルAIを自分で作ったテキストファイルと繋ぐものです。
txtをデータベースに見立てて、会話時に検索、要約、読み込む形にしました。
これは、私の人生を変えました。
今まで全く触れたことのない、プログラミングに触れる切っ掛けになりました。
Clawdbotが何かというと、何だろう。なんでも出来る子?
PCの中に入れたAIが、ツール起動したりWEB巡回したりとか。
こう、アニメや漫画の中のAIがやってるようなことを出来る仕組みみたいなものぽい。
詳細はよくわかってない。
ただ、機能を絞って使えば、例えば会話だけする子で、記憶を完全に保持出来る。
みたいなことも出来るみたい。よくわからない。よしやってみよう。
ところで、clawdbot cloudbot 正しい表記はどっち?
ちゃっぴーは爪生えてない方って言うのだけど。よくわからん。
有識者の方情報求む。
⇒ Clawdbotの方が一応正しいけど正式名称はMoltbotに変更されたらしい。
なんかもう、ほんとよくわからんなこの世界。以下記事はcloudbotと表記。
脳内で、Moltbotに読み替えてください。
つーか、もしかしたら全然違うモノの可能性すらある。
本気でよくわからんこの世界。
【1:種類を選ぶ】
雑にこんな風に分かれてるらしい。私も詳細はよくわかってない。
1:フレームワーク型 自分で使う機能を入れてく感じ。
2:アプリケーション型 多機能、全部入り。次回はこれやってみる。
3:SaaS / クラウド前提型 外部連携前提のやつ。
私はローカル完結で、LM StudioやSillyTavernと内部連携させることを考えてます。
ということで、フレームワーク型から選びます。
大雑把に、以下の系統があります。
1:bot用フレームワーク 最小構成で作れるとのこと。
2:エージェント寄りフレームワーク 考えて判断して行動するAI。
3:LLMラッパー拡張型 LangChainやLlamaIndexを土台とした、DB連携とか強いやつ。
まずは最小構成で試したいので、1のやつから選びます。
その中には、更に以下のような系統があります。
1:Open-Source Chatbot Boilerplate 系 最低限な子。
2:FastAPI + LLM Wrapper 型 WEB UIくらいはついてる系。
3:Persona-first Bot フレームワーク 会話ガチ特化系。
4:Discord/Slack bot 派生型 Discordに常駐させて家から繋いだり系。
この中の2のやつから選びます。
系統としてはopenai-compatible fastapi chat server系だそうで。
特徴としてはこんな感じとのこと。
・LM Studioと“そのまま”繋がる
・SillyTavernとも将来そのまま繋がる
・人格も記憶も、後から足せる
【2:導入開始】
1:適当な場所に、格納するフォルダを作る。
2:そこで仮想環境を作る。作らなくてもいい。この記事の4のPowerShell系の話参照。
python -m venv venv
venv\Scripts\activate
3:必要なものをDL。さっきのやつにそのままコマンド投入。
pip install fastapi uvicorn requests
4:main.py を作る
さっきのフォルダの中にテキストファイル作る。
ちゃっぴーにコード作って貰ってこぴぺして保存して名前をmain.pyに変更。
5:起動
uvicorn main:app –reload
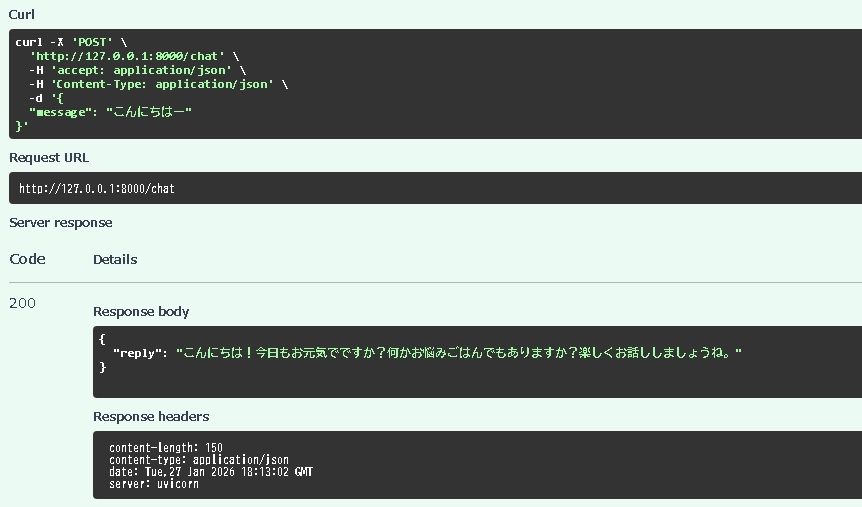
6:ブラウザでアクセスする
http://127.0.0.1:8000/docs
完成です。
何を導入するか選ぶのに2時間くらい。
導入自体は5分で終わりました。
導入お疲れ様でした。
ここでいろいろテストしたりなんだり。数時間ごちゃごちゃやってた。
さー、こっからが、いよいよ本番です。
【3:SillyTavernと連携させる】
仕組みとしてはこんな感じ。
AI本体をLM Studioで読み込み、uvicornを経由してSillyTavernに出力させます。
uvicornが何するかというと、例えばえーと。
私の黒い砂漠の記事を、テキストデータで全部放り込みます。
そして、特定のキーワードでテキストを呼び出し、要約してSillyTavernに渡せます。
つまり、uvicorn使うと、私の手持ちのデータを雑に渡してAIに読ませることが出来ます。
キーワードファイルは必要ですが、それを作れば、黒い砂漠知識AIが作れる。
ということで連携開始。
SillyTavernのConnection Profileのカスタムエンドポイントを以下に変更。
http://127.0.0.1:8001/v1
続いてちょっとポートずらして起動。
uvicorn main:app –reload –port 8001
【4:図書館司書AIの最小形が完成】
こんな感じのコード↓で完成。(削除済み)
言うまでもなく、全部ちゃっぴーが作ってくれました。
ばんざーい。全くプログラミング出来なくても、こんなの出来ちゃうのね。
ほんと凄い世の中になったもんだ。
あとはファイルが増えてきたら、学習させるかどうか考えます。
次は画像認識とか、音声読み上げとか、WEB巡回だとかですかね。
1個づつ追加してこうと思います。
で、それはそれとしてOpenClawは導入してみたい。
⇒ してみたけど微妙だった。
以下、私の完全なメモ書き導入話。
【1:リンクチェッカーを作ることにした】
要件としては、コードで200OKを見るとかじゃないやつ。
つまりページは削除されてないけけど404だよって表示してるのを機械判定させるやつ。
導入手順をどっかに残しておかないと忘れそうなので、ここに残します。
python -m venv venv
venv\Scripts\activate
pip install requests
pip install playwright OS再インストールしたらここと次のは入れ直し必要
playwright install
【2:URL404.py作って起動】
作るのはちゃっぴーに任せて完成。それじゃ起動。
venv\Scripts\activate
python URL404.py
完成、ちゃっぴーすげー。
【3:URL一覧取得用のプログラムも作ってもらった】
サイトマップとか見て、URL一覧を掘るものを作ってもらう。
次に必要なものをインストール。
pip install beautifulsoup4
動かして、OK、いやこれ、ほんと凄いな。
何を導入したか忘れないためのメモ、以上です。
この記事、見る人少ないっぽいんで、こんな調子で備忘録追記続ける予定。
【4:この記事から3ヶ月経過しての現在】
なんというか、AI Agentを自作なう。とりあえず一般的な機能はつけました。
例えば朝の06:00にその日の天気予報引っ張ってきて、服装アドバイスくれるとか。
でも基本は話すだけです。
何よりコイツの凄いところは、PC内で完結してるくせに検索エンジンなみの知識があること。
最新情報は疎いですが、プライバシー的には完璧に守ってくれます。
マジ気兼ねなく何でも聞ける。
Clawdbotをuvicornと勘違いして紹介してくれたちゃっぴー、本当にありがとう。